Frontend¶
Decoder¶
Nothing particular.
Physical register allocation¶
This is done by implementing a circular buffer containing the indexes of unallocated physical registers. This fits well into an FPGA with distributed ram.
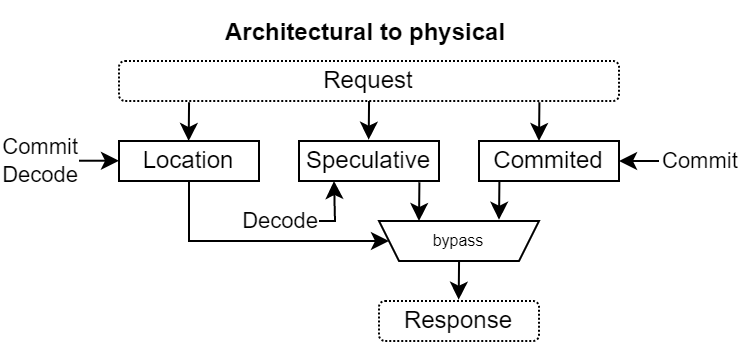
Architectural to physical¶
The translation from architectural register file to physical is done by implementing three tables :
Speculative mapping : Translate from architectural to physical, updated after the instruction decoding, implemented in distributed ram
Committed mapping : Translate from architectural to physical, updated after the instruction commit, implemented in distributed ram
Location : Translate from architectural to which mapping should be used (speculative or committed), implemented as register (need to be cleared on branch misprediction)
This allows to revert the state of the translation instantly when the pipeline predicted a branch wrong.
Physical to ROB ID¶
Once the physical register file of the dependencies is calculated, they are translated into the ROB ID on which it depends. This is done by two things :
ROB Mapping : A distributed ram which translates from physical to ROB ID
Busy : Which specify if the given ROB ID is still executing. It is set when a instruction is dispatched, cleared when the an instruction completes.
Dispatch / Issue¶
Here are a few specific points about the current implementation :
Unified design : Mostly to save area / having the most usage of each entry
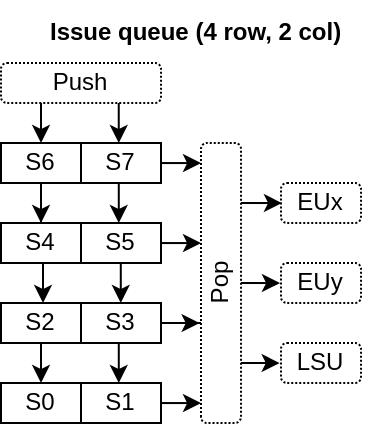
2D queue : The entries arranged in C=decodeCount columns L=slotCount/decodeCount rows
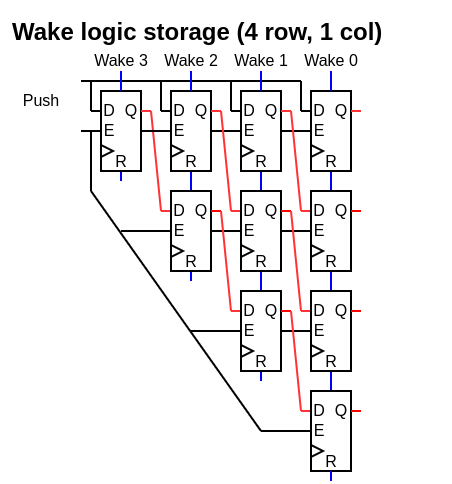
Row push : When something is pushed into the queue, a whole row is “consumed”, even if the row isn’t fully used
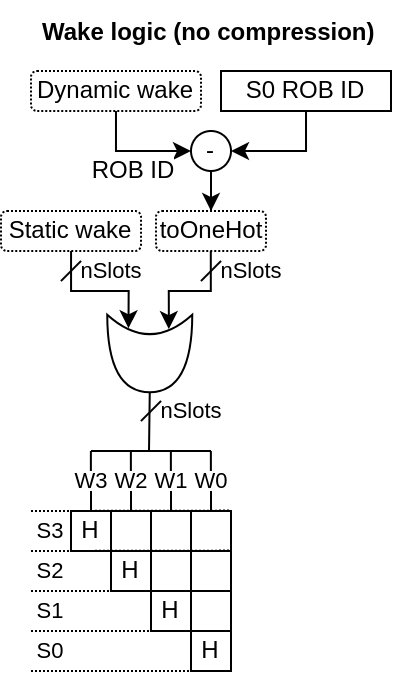
No compression : There is no compression for empty rows. The while queue is shifted by one row on each push. It allows for better inference of the matrix FF and a smaller/faster ROB ID wake logic.
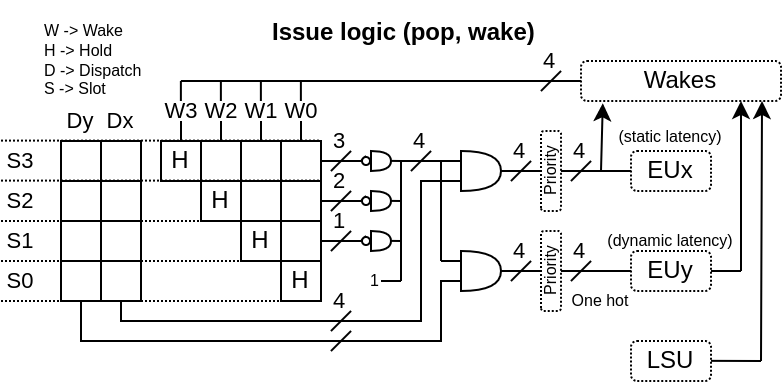
Matrix based : The storage of which instruction depends on what is done as a half matrix
Older first : If multiple instructions can be dispatched at once on a given execution unit, the older one is selected
Wake by ROB ID : For dynamic wakes, the ROB ID is used as the identifier (not the physical register file ID)
So, overall, a 32 slot queue seems to be a limit to not go beyond to preserve the timings. Also, with the current design, the area occupancy of the queue doesn’t seem to to be a big deal compared to the CPU as a whole.
Here are a few illustrations :