Decode
The Decode pipeline has a few tasks :
Translating the stream of fetched words into individual instructions
Figuring out instructions needs, mostly "does it need to read/write the register file ?"
Checking the execution lanes compatibility with incoming instruction. For instance, a memory load instruction can only be scheduled to the execute lane with the LSU
Ensuring that all branch prediction done in the fetch pipeline were done on real branch instructions.
Feed the execution lanes with instructions
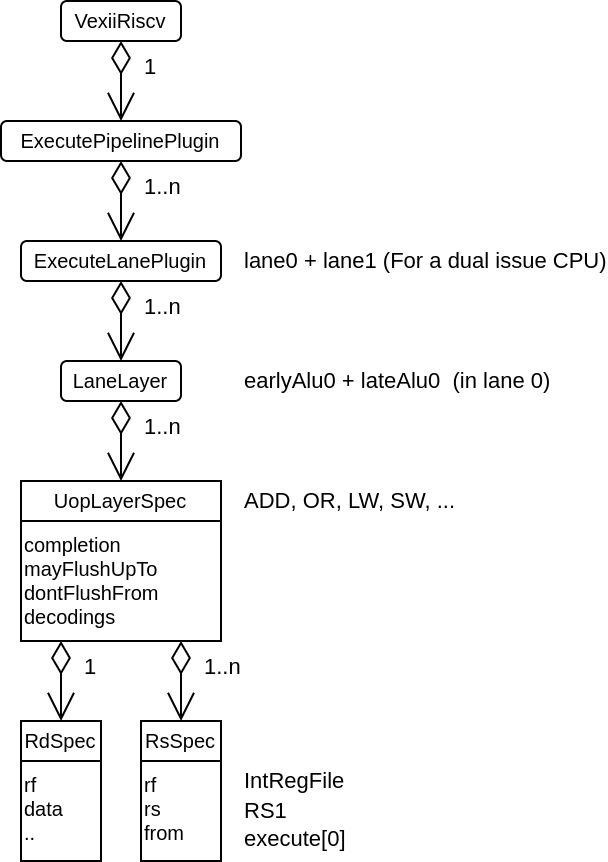
DecodePipelinePlugin
Provide the pipeline framework for all the decode related hardware. It use the spinal.lib.misc.pipeline API but implement multiple "lanes" in it.
AlignerPlugin
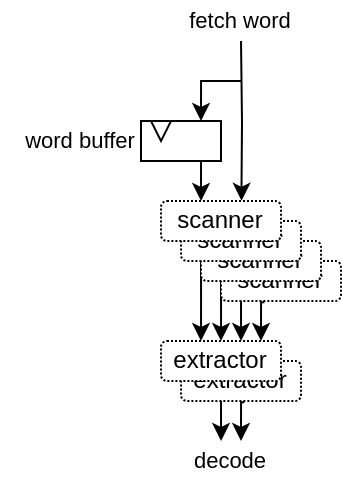
Decode the words from the fetch pipeline into aligned instructions in the decode pipeline. Its complexity mostly come from the necessity to support having RVC [and BTB], mostly by adding additional cases to handle.
RVC allows 32 bits instruction to be unaligned, meaning they can cross between 2 fetched words, so it need to have some internal buffer / states to work.
The BTB may have predicted (falsely) a jump instruction where there is none, which may cut the fetch of an 32 bits instruction in the middle.
The AlignerPlugin is designed as following :
Has a internal fetch word buffer in oder to support 32 bits instruction with RVC
First it scan at every possible instruction position, ex : RVC with 64 bits fetch words => 2x64/16 scanners. Extracting the instruction length, presence of all the instruction data (slices) and necessity to redo the fetch because of a bad BTB prediction.
Then it has one extractor per decoding lane. They will check the scanner for the firsts valid instructions.
Then each extractor is fed into the decoder pipeline.
DecoderPlugin
Will :
Decode instruction
Generate illegal instruction exception
Generate "interrupt" instruction
Ensure that no instruction predicted as a branch/jump by the BTB (but isn't a branch/jump) doesn't goes any further. (See more in the Branch prediction chapter)
DispatchPlugin
This is probably the hardest part of the VexiiRiscv hardware description to read, as it does a lot of elaboration time computing in order to figure out what hardware need to be generated.
The function of the plugin is to :
Collect instruction from the end of the decode pipeline
Dispatch them on the multiple "execution layers" (Execution lanes's ALUs) available when all dependencies are done.
Architecture
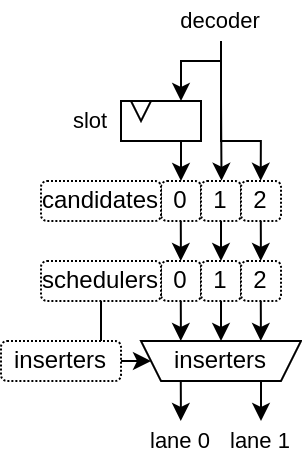
Here is a diagram of the DispatchPlugin hardware for a dual issue VexiiRiscv :
Here is a few explanation about execute lanes and layers :
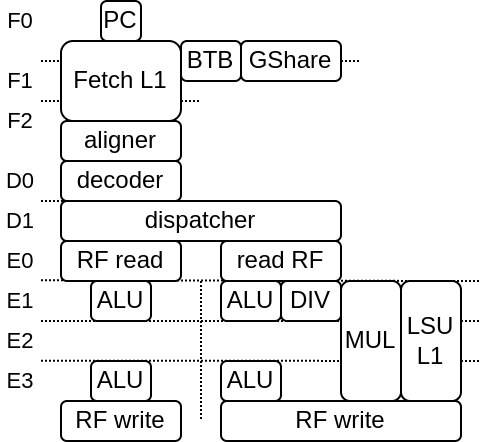
A execute lane represent a path toward which an instruction can be executed.
A execute lane can have one or many layers, which can be used to implement things as early ALU / late ALU
Each layer will have a static scheduling priority
The DispatchPlugin doesn't require lanes or layers to be symmetric in any way.
Here is an picture example of VexiiRiscv with 2 execution lanes and 2 layer per execution lane. the 2 execution lanes are separated left and right in stages E1-E2-E3.
Left E1 ALU is one layer, with highest priority, as it provide the best timings and keep the LSU/MUL/DIV path free
Right E1 ALU/DIV/MUL/LSU is one layer, with high priority, as it provide the best timings but it does allocate the MUL/LSU path as well (even if the instruction doesn't need it)
Left E3 ALU is one layer, with low priority, as it provide a late ALU result (bad for dependencies).
Right E3 ALU is one layer, with lowest priority, as it provide a late ALU result and also allocate the MUL/LSU path as well.
Here are a list of things that the schedulers need to take in account to know on which layer an instruction could be scheduled :
Check if, in the future (after the instruction side-effects timing), the instruction could be flushed by an already scheduled instruction
Check at which stage of the execute pipeline the instruction need its RS (operands) to be readable (this is the main feature allowing late-alu)
Check if the timing at which the instruction would use shared resources would conflict with something already scheduled
Check if a instruction fence is pending
And a few other minor things
The inserter will then select which candidates instruction can be executed in which execution lane / layer depending the instruction order and layer priorities.
Elaboration
This is what make the DispatcherPlugin quite special. During elaboration time, it look at the specification of every execution lane's layers, to figure out which instruction it supports and what are its dependencies / limitations, and then try to generate a scheduler for it.