FPU
The VexiiRiscv FPU has the following characteristics :
By default, It is fully compliant with the IEEE-754 spec (subnormal, rounding, exception flags, ..)
There is options to reduce its footprint at the cost of compliance (reduced FMA accuracy, and drop subnormal support)
It isn't a single chunky module, instead it is composed of many plugins in the same ways than the rest of the CPU.
It is tightly coupled to the execute pipeline
All operations can be issued at the rate of 1 instruction per cycle, excepted for FDIV/FSQRT/Subnormals
By default, it is deeply pipelined to help with FPGA timings (10 stages FMA)
Multiple hardware resources are shared between multiple instruction (ex rounding, adder (FMA+FADD)
The VexiiRiscv scheduler take care to not schedule an instruction which would use the same resource than an older instruction
FDIV and FMUL reuse the integer pipeline DIV and MUL hardware
Subnormal numbers are handled by recoding/encoding them on operands and results of math instructions. This will trigger some little state machines which will halt the CPU a few cycles (2-3 cycles)
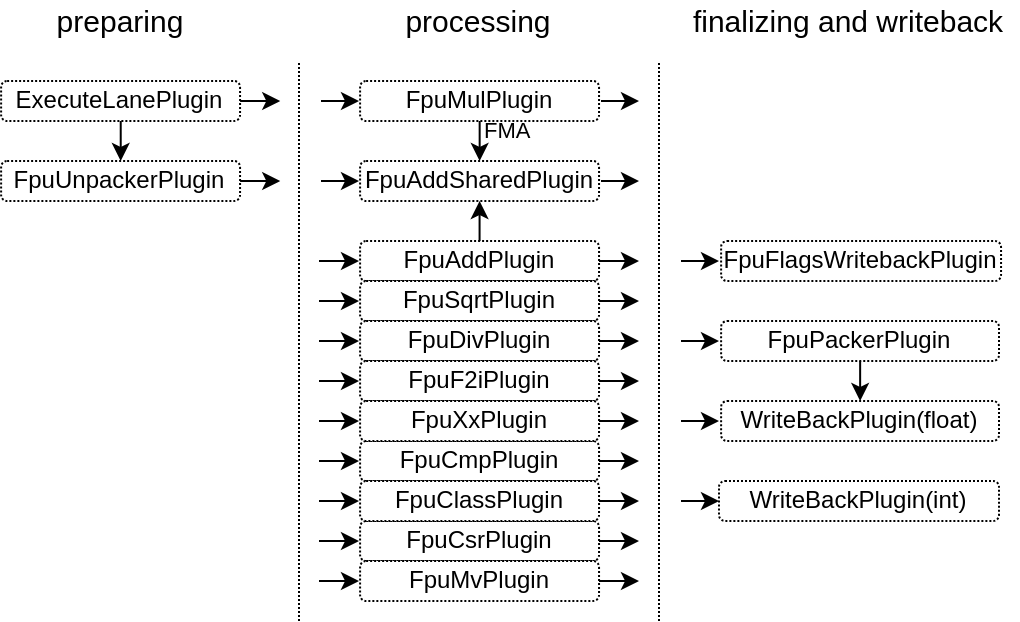
Plugins architecture
There is a few foundation plugins that compose the FPU :
FpuUnpackPlugin : Will decode the RS1/2/3 operands (isZero, isInfinity, ..) as well as recode them in a floating point format which simplify subnormals into regular floating point values
FpuPackPlugin : Will apply rounding to floating point results, recode them into IEEE-754 (including subnormal) before sending those to the WriteBackPlugin(float)
WriteBackPlugin(float) : Allows to write values back to the register file (it is the same implementation as the WriteBackPlugin(integer)
FpuFlagsWriteback ; Allows instruction to set FPU exception flags
Area / Timings options
To improve the FPU area and timings (especially on FPGA), there is currently two main options implemented.
The first option is to reduce the FMA (Float Multiply Add instruction A*B+C) accuracy. The reason is that the mantissa result of the multiply operation (for 64 bits float) is 2x(52+1)=106 bits, then we need to take those bits and implement the floating point adder against the third operand. So, instead of having to do a 52 bits + 52 bits floating point adder, we need to do a 106 bits + 52 bits floating point adder, which is quite heavy, increase the timings and latencies while being (very likely) overkilled. So this option throw away about half of the multiplication mantissa result.
The second option is to disable subnormal support, and instead consider those value as normal floating point numbers. This reduce the area by not having to handle subnormals (it removes big barrels shifters) , as well as improving timings. The down side is that the floating point value range is slightly reduced, and if the user provide floating point constants which are subnormals number, they will be considered as 2^exp_subnormal numbers.
In practice those two option do not seems to creates issues (for regular use cases), as it was tested by running debian with various software and graphical environments.
Optimized software
If you used the default FPU configuration (deeply pipelined), and you want to achieve a high FPU bandwidth, your software need to be careful about dependencies between instruction. For instance, a FMA instruction will have around 10 cycle latency before providing its results, so if you want for instance to multiply 1000 values against some constants and accumulate the results together, you will need to accumulate things using multiple accumulators and then, only at the end, aggregate the accumulators together.
So think about code pipelining. GCC will not necessary do a got job about it, as it may assume assume that the FPU has a much lower latency, or just optimize for code size.