Introduction
In a few words, VexiiRiscv :
Is an project which implement an hardware CPU as well as a few SoC
Follows the RISC-V instruction set
Aims at covering most of the in-order CPU design-space. From small microcontroller to applicative multi-core systems
Can run baremetal applications aswell as Linux / Buildroot / Debian / ...
Is free / open-source (MIT license) (https://github.com/SpinalHDL/VexiiRiscv)
Should fit well on all FPGA families but also be portable to ASIC
Other doc / media / talks
Here is a list of links to resources which present or document VexiiRiscv :
FSiC 2024 : https://wiki.f-si.org/index.php?title=Moving_toward_VexiiRiscv
COSCUP 2024 : https://coscup.org/2024/en/session/PVAHAS
ORConf 2024 : https://fossi-foundation.org/orconf/2024#vexiiriscv--a-debian-demonstration
Running debian with VexiiRiscv : https://youtu.be/dR_jqS13D2c?t=112
Scala doc : https://spinalhdl.github.io/VexiiRiscv/doc/vexiiriscv/index.html
Glossary
Here is a few acronyms commonly used across the documentation :
CPU : Central Processing Unit. A CPU core refer to the hardware which is capable of executing software but without all the peripherals and memory interconnect that could be on the same chip.
HART : Hardware Thread. One CPU core can for instance implement multiple HART, meaning that it will execute multiple threads concurently. For instance, most modern PC CPUs implements 2 Hardware Thread per CPU core (this feature is called hyper-threading)
RF : Register file. Local memory on the CPU used by most instructions to read their operands and write their results.
CSR : Control Status Register, those are the special register in the CPU which allows to handle interruptions, exceptions aswell as configuring things like the MMU.
ALU : Arithmetic Logical Unit. Were most of the integer processing is done (add, sub, or, and, ...)
FPU : Floating Point Unit
LSU : Load Store Unit. This is the part of the CPU which will mostly keep track of inflight load and store instructions to ensure proper memory ordering and interface with the L1 data cache.
AMO : Atomic Memory Operation. Set of instruction which allows to read-modify the main memory with a single access. No other memory access can be observed to happen in between the read and modify operations.
MMU : Memory Management Unit. Translate virtual addresses into pyhsical ones, aswell as check access permitions.
PMP : Physical Memory Protection. Check physical address access permitions.
I$ : Instruction Cache
D$ : Data Cache
IO : Input Output. Most of the time it mean LOAD/Store instruction which target peripherals (instead of general purpose memory)
PC : Program Counter. The address at which the CPU is currently executing instructions.
Here is a few more terms commonly used in the CPU context:
Fetching : The act of reading the data which contains the instructions from the memory.
Decoding : Figuring out what should be done in the CPU for a given instruction.
Dispatching : Sending a given instruction to one execution units, once all its dependencies are available.
Executing : Processing the data used by an instruction
Commiting : Going past the point were a given instruction can not be canceled/reverted anymore.
Trap : A trap is an event which will stop the execution of the current software, and make the CPU start executing the software pointed by its trap vector.
Interrupt : An interrupt is a kind of trap which is generaly comming from the outside. Ex : timer, GPIO, UART, Ethernet, ...
Exception : An exception is a kind of trap which is generated by the program the CPU is currently running, for instance an misaligned memory load, a breakpoint, ...
Here is a few more terms commonly used when talking about caches :
Line : A cache line is a block of memory in the cache (typicaly 64 bytes) which will act as a temporary copy of the main memory.
Way : The number of ways in a CPU specifies how many cache lines could be used to map a given address interchangeably. A high number of ways gives the CPU more choices, when a new cache line need to be allocated, to evict the least usefull cache line.
Set : The number of sets specifies how parts of the cache lines addresses are staticaly mapped to portions of the memory.
Refill : The action which load a cache line with a new memory copy
Writeback : The action which free a modified cache line by writting is back to the main memory
Blocking : A blocking cache will not accept any new CPU request while performing a refill or a writeback
Prefetching : Anticipating future CPU needs by refilling yet unrequested memory blocks in the cache (driven by predictions)
Here is a few more terms commonly used when talking about branch prediction :
BTB : Branch Target Buffer. The goal of this hardware unit is to predict what instructions are at a given memory address. ex : Could it be a branch or a jump ? If it is, where would it branch/jump toward ?
RAS : Return Address Stack. Used to predict where return instruction should jump, by implementing a stack which is pushed on call instructions, and popped on ret instructions.
GShare : This is a branch prediction technique which try to correlate branche instruction addresses, the CPU history of taken/non-taken branches and a table of taken/non-taken bias to predict future branch instruction behaviour.
Technicalities
VexiiRiscv is a from scratch second iteration of VexRiscv, with the following goals :
To implement RISC-V 32/64 bits IMAFDCSU
Could start around as small as VexRiscv, but could scale further in performance
Optional late-alu
Optional multi issue
Providing a cleaner implementation, getting ride of the technical debt, especially the frontend
Scale well at higher frequencies via its hardware prefetching and non blocking write-back D$
Proper branch prediction
...
On this date (07/01/2025) the status is :
RISC-V 32/64 IMAFDCSU supported (Multiply / Atomic / Float / Double / Supervisor / User)
Can run baremetal applications (2.50 dhrystone/MHz, 5.24 coremark/MHz)
Can run linux/buildroot/debian on FPGA hardware (via litex)
single/dual issue supported
early + late alu supported
BTB/RAS/GShare branch prediction supported
MMU SV32/SV39 supported
PMP supported
LSU store buffer supported
Multi-core memory coherency supported
Non-blocking I$ D$ supported
Hardware/Software D$ prefetch supported
Hardware I$ prefetch supported
JTAG debug supported
Cache-Block Management Instructions (CBM) supported (Allows software based memory coherency via flush, clean, invalidate instructions)
Hardware watchpoint supported
Supports AXI4 / Wishbone / Tilelink memory buses (RVA is not available in some configs, see the SoC main page)
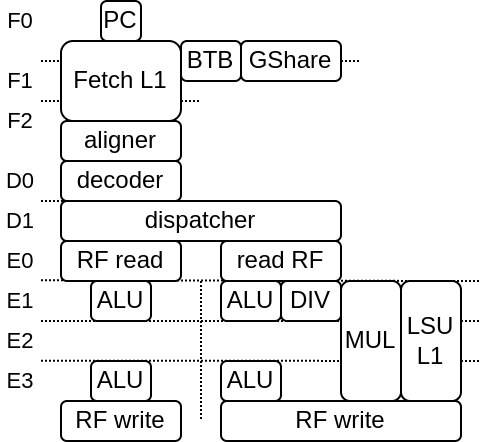
Here is a diagram with 2 issue / early+late alu / 6 stages configuration (note that the pipeline structure can vary a lot):
About RISC-V
To help onboarding, here is a few thing about RISC-V :
RISC-V isn't a CPU / CPU architecture
RISC-V is a Instruction Set Architecture (ISA), which mean that from a CPU perspective, it mostly specify the instructions that need to be implemented, and their behaviour.
RISC-V has 4 main specification :
Unprivileged Specification : Mainly specify the integer, floating point and load / store instructions
Privileged Specification : Mainly specify all the special CPU registers which can be used to handle interruptions, exceptions, traps, virtual memory, memory protections, machine/supervisor/user privilege modes
RISC-V calling convention : Mainly specify how the registers can be used by functions to pass parameters, aswell as providing an alternative name for each of the registers (ex : x2 become the stack pointer, named sp)
RISC-V External Debug Support : Mainly specify how the CPU can support JTAG debug, hardware breakpoints and triggers
To figure out more about those specification, check https://riscv.org/technical/specifications/
About VexRiscv (not VexiiRiscv)
There is few reasons why VexiiRiscv exists instead of doing incremental upgrade on VexRiscv
Mostly, all the VexRiscv parts could be subject for upgrades
VexRiscv frontend / branch prediction is quite messy
The whole VexRiscv pipeline would have need a complete overhaul in oder to support multiple issue / late-alu
The VexRiscv plugin system has hits some limits
VexRiscv accumulated quite a bit of technical debt over time (2017)
The VexRiscv data cache being write though start to create issues the faster the frequency goes (DRAM can't follow)
The VexRiscv verification infrastructure based on its own golden model isn't great.
So, enough is enough, it was time to start fresh :D